
ChatGPT o3 and the Architecture of Reason: Beyond the AI Wall
Does Real Reasoning Require Knowing When Not to Pursue a Thought?


Figure 1. ARC-AGI Task.
Welcome to 2025! I have high hopes for this year as a time when our collective work responding to AI systems will progress meaningfully - addressing their disruption, embracing their invitation to begin curriculum reform, and building thoughtfully on existing generative learning practices.
We're seeing more schools lean into the essential work: choosing appropriate tools for their teachers and students, developing sound policies, training staff and faculty, all while maintaining the flexibility needed to adapt to continuing advances. Here at Educating AI, we've chosen to skip the traditional "best of 2024" posts or forecasts for 2025 that populate Substack this time of year. Instead, we're continuing our focus on building sound practices and responses.
If you missed it, we had an important post last week about what
recently aptly described as "lateral reading" strategies. For those looking to build productive resistance into your own or your students' work with AI systems, we have much to learn by re-studying media literacy and adapting those lessons to this new context.A heartfelt thanks to all our new paid subscribers - I feel honored that you find this content valuable enough to commit some of your resources to supporting our weekly work here. And stay tuned: next week brings an exciting article from Marta Napiorkowska of St. Luke's School in CT on the neurochemical riches that come from immersing oneself in traditional writing processes.
Beyond the Wall
Days after I published "Will Artificial Intelligence Hit a Wall?" in Persuasion this December, OpenAI's o3 model achieved something remarkable: it became the first AI system to surpass human performance on François Chollet's ARC-AGI test.

Figure 2. Another ARC-AGI Task.
As Chollet notes, o3 demonstrated "a surprising and important step-function increase in AI capabilities, showing novel task adaptation ability never seen before." The timing was ironic. My piece had just argued that AI improvements were slowing dramatically, with new models showing only modest gains despite massive investment.
But o3's success doesn't simply contradict that assessment - it complicates it in fascinating ways. The model succeeded not through the brute force scaling that has dominated AI development, but through what Chollet calls "a huge amount of test-time search" - a fundamentally different architectural approach that allows the system multiple attempts to work through problems. Where previous models peaked at 55% accuracy on ARC-AGI, well below human performance, o3 achieved 87.5% by effectively thinking longer about each problem.
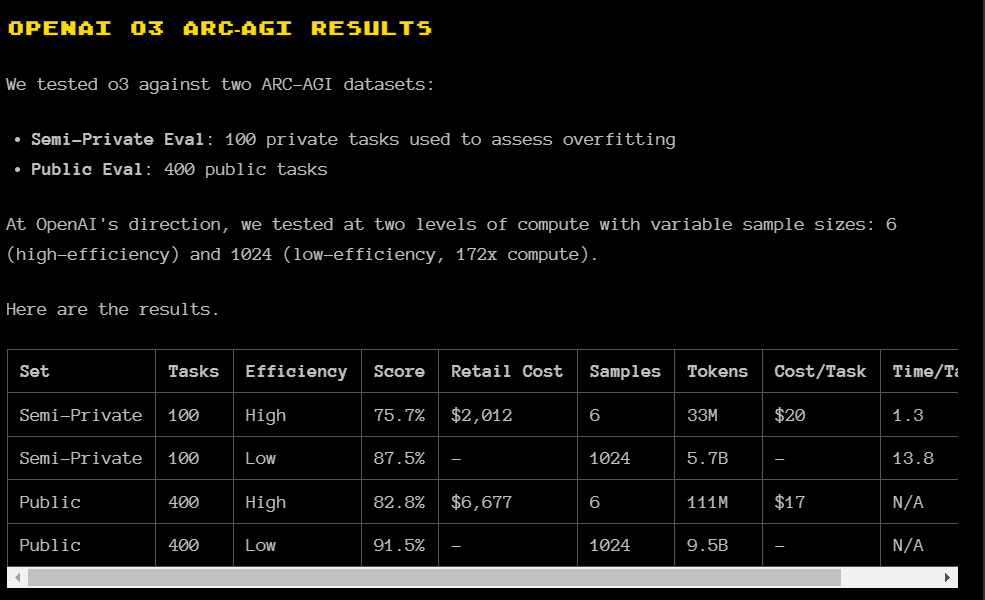
Figure 3. Image of ChatGPT o3’s results on ARC Prize page.
This development forces us to look deeper at not just the trajectory of AI progress, but at the nature of machine reasoning itself. Two recent analyses crystallize the debate. Writing his important piece “Why Large Language Models Cannot (Still) Actually Reason,”
argues that language models remain "incapable, by design, of perfect reasoning." offers a contrasting perspective in “Critical Reasoning with AI: How we know LLMs are applying reasoning patterns, and not just reverse image searching,” suggesting we evaluate AI reasoning not by its internal processes but by its ability to produce "valid reasons."Beyond Pattern-Matching: How O3 Works
Unlike models prior to ChatGPT O Series, O3's innovation lies not in raw computational power but in its approach to reasoning. Where models prior to ChatGPT O Series relied primarily on pattern recognition drawn from massive training datasets, O3 takes a fundamentally different route. It leverages a process known as "test-time compute," through which AI models explore multiple potential solutions even after training is complete, using varying amounts of inference-time search to tackle each problem. As François Chollet notes, O3 processes millions of tokens per puzzle, exhaustively scouring "the space of possible Chains of Thought."

Figure 4. François Chollet, Google AI researcher and creator of Keras.
This shift becomes clear in the ARC-AGI results. Prior models had plateaued around 55% accuracy—well below human performance—suggesting a fundamental limit to what pattern matching alone could achieve. O3’s jump to 87.5% represents not just an incremental improvement but a qualitative leap in how AI systems approach novel problems. Instead of just recognizing patterns, O3 appears capable of deducing broad rules from sparse examples.
Harry Law captures the game-changing nature of O3 succinctly in his Learning from Examples Substack:
“The significance of O3 is that OpenAI has found a way to increase the effectiveness of a model in tandem with the amount of compute expended at inference time. That might not sound like a massive deal, but it represents probably the single-biggest step jump in capability seen since the release of GPT-2 five years ago.”
Yet significant limitations remain. O3 still fails at tasks that humans find almost trivial—like moving colored squares according to basic patterns. As Chollet notes, these failures underscore “fundamental differences with human intelligence.” The model requires hours of intensive computation to solve problems that humans handle in minutes. Despite matching (and at times exceeding) human performance on certain abstract reasoning tasks, it relies on radically different means to get there—means that may or may not generalize to broader real-world challenges.
Two Views of Machine Reasoning
The debate over what constitutes "reasoning" lies at the heart of o3's achievement. Two recent analyses offer sharply contrasting frameworks for evaluating AI capability. Alejandro Piad Morffis's essay builds a rigorous case against machine reasoning, while Mike Caulfield's essay suggests we focus instead on the validity of AI-generated reasoning paths. Their arguments illuminate both the promise and limitations of o3's approach.
Morffis’s Three Constraints
Morffis contends that large language models remain “incapable, by design, of perfect reasoning.” He highlights three core limits:
Probabilistic Foundations: Even with zero temperature sampling, language models rely on statistical patterns.
Fixed Computational Budget: They dedicate the same resources to simple and complex problems alike.
Lack of Turing Completeness: They cannot handle truly open-ended computation.
For Morffis, these aren’t mere technical hiccups but deep structural barriers. Even O3’s “test-time compute” approach, he argues, merely extends the model’s computational budget without confronting what he sees as the fundamental challenge: “approximate reasoning is not good enough” for mission-critical tasks.
Caulfield’s Alternative Approach
In contrast, Caulfield maintains that much of human reasoning isn’t a step-by-step chain of logic but rather a post-hoc rationalization. From his perspective:
Justification Over Process: It matters less how we arrive at conclusions and more whether we can provide valid reasons for them.
Post-Hoc Rationalization: Humans often construct explanations after the fact, which nonetheless pass as plausible accounts of “how we thought.”
Accepting Partial Evidence: In everyday life—checking expired milk, interpreting snapshots—we frequently trust someone’s conclusion without seeing each step of their thought process.
Taken together, Morffis and Caulfield frame two very different visions of machine reasoning. Where Morffis stresses technical ceilings—how models fundamentally cannot do certain things—Caulfield highlights our tendency to validate reasoning by the persuasiveness of its final form, irrespective of how it came about.

Rethinking Progress and Judgment
The implications of o3's breakthrough extend beyond technical debates about AI capability. What we're seeing isn't the exponential leap to artificial general intelligence that some predict, but rather a methodical expansion of what's possible through architectural innovation. As Chollet observes, "o3 still fails on some very easy tasks, indicating fundamental differences with human intelligence." Yet its approach to solving novel problems through exhaustive exploration forces us to examine what we mean by reasoning itself.
This has immediate practical implications. While Morffis is right that we wouldn't want probabilistic reasoning in nuclear safety systems, his insistence on Turing-completeness sets the bar for "true reasoning" so high that it excludes most of what we recognize as human reasoning outside pure mathematics. And while Caulfield's focus on verifiable reasoning paths opens up an intriguing alternative perspective, it offers primarily a descriptive analysis of what reasoning looks like from the outside.
The missing link is judgment - not just decision-making, but a meta-cognitive capacity that knows when to stop analyzing, when to shift frameworks entirely, and when to acknowledge that more computation won't yield better results. It's what allows a chess master to know which positions merit deep calculation and which require intuitive play, or what enables a doctor to know when to order more tests versus when to act on available information.
The humanities have long grappled with this relationship between reasoning and judgment. From Aristotle's concept of phronesis (practical wisdom) to Kant's faculty of judgment to contemporary discussions of tacit knowledge, humanistic traditions suggest that judgment isn't just efficient reasoning - it's a fundamentally different kind of cognitive activity. Neither Morffis's machine learning perspective nor Caulfield's analytical framework fully captures this dimension.

When Walls Become Questions

My earlier assessment of AI hitting a wall wasn't wrong so much as incomplete. When walls manifest, innovation finds ways around them. But o3's achievement suggests the real barriers may lie not in computational limits but in the nature of judgment itself. The question is no longer whether AI can produce reasoning-like outputs - clearly it can, through exhaustive exploration of possible paths. The deeper question is how computational approaches to reasoning can complement rather than replace human judgment.
This understanding suggests specific approaches to AI deployment. In education, AI systems might excel at demonstrating multiple reasoning paths, while human teachers guide students in developing the judgment to know which paths are worth pursuing. In professional contexts, AI might exhaustively explore possible arguments while human experts exercise judgment about which arguments merit deeper consideration. The goal isn't to replicate human judgment - which may be computationally impossible - but to create productive partnerships between computational thoroughness and human discernment.
This gap between computational power and human judgment may prove more fundamental than either AI skeptics or enthusiasts imagine. While we can expect continued improvements in AI's ability to explore and verify reasoning paths, the ineffable quality of human judgment - our ability to know not just how to compute, but when to stop computing - points to something beyond mere computation. The wall hasn't disappeared; it has transformed into a more profound question about how to combine the exhaustive exploration of machines with the fluid judgment that characterizes human thought.
Nick Potkalitsky, Ph.D.
Check out some of our favorite Substacks:
Mike Kentz’s AI EduPathways: Insights from one of our most insightful, creative, and eloquent AI educators in the business!!!
Terry Underwood’s Learning to Read, Reading to Learn: The most penetrating investigation of the intersections between compositional theory, literacy studies, and AI on the internet!!!
Suzi’s When Life Gives You AI: An cutting-edge exploration of the intersection among computer science, neuroscience, and philosophy
Alejandro Piad Morffis’s Mostly Harmless Ideas: Unmatched investigations into coding, machine learning, computational theory, and practical AI applications
Michael Woudenberg’s Polymathic Being: Polymathic wisdom brought to you every Sunday morning with your first cup of coffee
Rob Nelson’s AI Log: Incredibly deep and insightful essay about AI’s impact on higher ed, society, and culture.
Michael Spencer’s AI Supremacy: The most comprehensive and current analysis of AI news and trends, featuring numerous intriguing guest posts
Daniel Bashir’s The Gradient Podcast: The top interviews with leading AI experts, researchers, developers, and linguists.
Daniel Nest’s Why Try AI?: The most amazing updates on AI tools and techniques
Riccardo Vocca’s The Intelligent Friend: An intriguing examination of the diverse ways AI is transforming our lives and the world around us.
Jason Gulya’s The AI Edventure: An important exploration of cutting edge innovations in AI-responsive curriculum and pedagogy.
Here is a great comment from Terry Underwood that he left in Substack Notes. Recording here for posterity: I’d love to hear Mike and Alejandro discuss this issue. Great work on this piece, Nick; nice demonstration of phronesis in your decision not to go all prophet on the future of AI.
When I think “I know how this situation ends and this is what I’m going to do,” I’m reasoning not just from past training and experience but from immediate cognizing of what is likely to occur in the future based on the present. EVs as AI can accomplish this feat but that’s it, and they are fifty grand a pop. LLMs cannot cognize the deadline of the present unless I tell it how I see things right now. And even then there is a time lag.
I know how this plays out and act on it. I’m going to eat this apple. Mike deals with this gap between AI and humans pointing to this tacit knowledge of apples. AI cannot make these decisions and never will because AI simply is not human but a machine. It can’t eat apples. Weighing and describing the apple is AI. Alejandro uses tacit knowledge in his human existence, also, but that’s not his concern re: the AI gap. He’s looking explicitly at formal reasoning processes involving abstract symbols that follow unambiguous rules. Mike and Alejandro are apples and oranges. Mike takes a bite of the apple because he’s hungry. Alejandro carefully peels the orange, separates the slices, analyzes the chemical components—not to eat the orange, but to explain how the orange functions when it is eaten. Alejandro is into computational thinking.
You and by extension Mike are calling "tacit knowledge" what a philosopher might call "embedded and embodied understanding." This kind of knowledge isn't abstract or purely reasonable. It’s knowledge in action, of consequence in physical reality. A chef knows when dough feels right. A carpenter knows the behavior of different woods. A parent knows their child's cry.
AI judgments, in contrast, are essentially, always abstract even when it discusses flies laying eggs in apples. AI can process patterns in training data and now process patterns in patterns in training data, but it can’t judge as humans can because it can’t suffer the consequences.
AI can’t write because it has no audience. It generates output that looks like text but isn’t the same.
AI has no skin in the game. Humans have had skin in the game for millions of years. Computer science hasn’t had a thing to do with designing the brain. In a non-trivial way our brains had a hand or two and some eyes, ears, etc. in their design.
This creates an inherent AI limitation. My judgments, however sophisticated or flawed they might appear, are always anchored in physical reality where actual consequences unfold. AI can analyze cooking temperatures and their effects on a potato, but it can never truly know what leather and ash tastes like. AI can “discuss” emotional responses, but it can never feel fear or joy that might influence its, ahem, judgment.
This suggests that AI systems are better understood as tools for augmenting human judgment (reference materials, heuristics) rather than replacing it. AI can process information and identify patterns, but the final integration with reality, the real knowing that leads to action, that remains fundamentally human. And until AI grows a skin with neural loops linked to a natural pain and pleasure palace, for my money it will never do better than emulate human judgment. Just look at Mike and Alejandro. AI isn’t going to settle this. I’d need to listen in real time to these highly skilled and intuitive thinkers. Your post suggests that you would be an excellent moderator of the discussion to help those of us lacking expertise in Toulman analysis, a strategy for reasoning in situations where there is no absolute truth, no right or wrong, and computational analysis, where there is a right answer.
Happy New Year, Nick!
2025 promises to be fascinating to observe, with o3 likely paving the way for most AI labs playing catchup with test-time compute "thinking" models of their own. We've already seen DeepSeek V3 (Deep Think mode) and Gemini Flash Thinking from Google, and I'm sure we'll see more in the months to come.